
c plus plus
cpp知识补充
01 - 侯捷 - C++面向对象高级开发(上下两部曲)
02 - 侯捷 - STL标准库和泛型编程
03 - 侯捷 - C++设计模式
04 - 侯捷 - C++新标准C++11&14
05 - 侯捷 - C++内存管理机制
06 - 侯捷 C++ Startup 揭密:C++ 程序的生前和死后
07、算法原理与实践(选修)
08、系统设计与实践(选修)
书籍:c++ primer
effective modern c++
stl源码剖析
前言
拿来当c++知识点补充库,顺序不是按照学习的顺序,是感觉哪个不会了,看书或视频补充知识点。
namespace
定义命名空间1
2
3
4
5
6
7
8
9
10
11
12
13//如果不引入 using namespace std;就需要我们显示引入,例如std::cout
namespace a
{
int a = 10;
}
namespace b
{
int a = 20;
namespace c
{
int a = 30;
}
}
使用命名空间1
2
3
4
5
6
7
8
9
10
11
12
13void main()
{
using namespace a;
using namespace b;
cout << a::a << endl;
cout << b::a << endl;
cout << b::c::a << endl;
using b::c::a;
cout << a;
system("pause");
}
不使用using namespace std 原因:
如果没有命名空间,这些变量、函数、类的名称将都存在于全局命名空间中,当定义了一个函数名与标准库中函数名相同时,就会发生冲突。
比如,我们在自己的程序中定义了一个Stack类,而我们程序中使用的某个库中也可能定义了一个同名的类,此时名称就冲突了。
顶层const和底层const
const修饰的变量不可以改变就是顶层const:
const int a = 10;
底层const:
const int &ra = 10;
c++ primer :当执行对象的拷贝操作时,常量的顶层const不受什么影响,而底层const必须一致
const引用理解:
1.引用不是对象且不进行拷贝
2.常量引用如果在左侧,右侧可以接任何东西
3.非常量引用 = 常量 error
4.引用如果在等号右侧请忽略引用
5.非常量 = 常引用
判断方法:

代码详解:1
2
3
4
5
6
7
8
9
10void main()
{
int i = 0;
const int p = 10;//顶层const(不能被修改)
const int* p1 = &p;
p1 = &i;
//底层const 允许修改p1的值 const 修饰的是int 不能改变的是 *p1 int *p1是个指针,地址没变,里面值改变无所谓 const修饰的是什么,p1就指向的是什么 *p就相当于(const int)*p
int* const p2 =&i;//顶层const p2的值不允许被修改 p2是个指针,里面存放的是地址,地址是不可以改变的,值是可以改变的。 const int*p2 然后你可以通过改变p2指向这个内存地址里的值,来改变p2读出来的值
system("pause");
}
const int* p1 = &p;
p1是一个指向const int类型的指针变量。
&p是一个指向int类型变量p的地址。
通过将&p赋值给p1,p1成为了一个指向p的const int类型的指针。
这意味着p1指向的int类型的数据是只读的,不能通过p1来修改。
int* const p2 = &i;
p2是一个指向int类型的常量指针变量。
&i是一个指向int类型变量i的地址。
通过将&i赋值给p2,p2成为了一个指向i的int类型的常量指针。
这意味着p2指向的int类型数据可以修改,但是p2本身的指向是不可变的,即p2不能指向其他的地址。
register 加强
register 关键字请求编译器将局部变量存储于寄存器中。1
2
3
4
5
6void main()
{
register int a = 0;
std::cout<<&a<<endl;
system("pause");
}
引用剖析
引用语法
1 | void main() |
引用本质
引用在c++内部实现是一个常量指针
Type& name<——>Type * const name
函数返回值是引用
1 | int *get_1() |
若返回静态变量或全局变量
可以成为其他引用初始值
既可以作为右值使用,也可以作为左值使用
1 | int g1() |
inline 内联函数
用来代替宏代码片段1
2
3
4
5
6
7
8
9 inline void fun()
{
int a = 10;
cout<<a<<endl;
}
void main()
{
}1
2
3
4
5
6
7
8
9
10
11 #define Myfunc(a,b)((a)<(b)?(a):(b))
inline int myfunc(int a,int b)
{
return a<b?a:b
}
int main()
{
int c1 = myfunc(++a,b)//a=2 b = 3 c =2
int c2 = Myfunc(++a,b)//==>宏展开((++a)<(b)?(++a):(b))
return 0;
}
内联不能做声明,必须和函数体实现写在一块
adsd
构造函数和析构函数
基本概念
构造函数:完成对属性的初始化工作(先创建的对象先构造)
析构函数:先创建的对象后释放(栈机制)
构造函数分类
1 | class test |
深拷贝和浅拷贝问题
浅拷贝分析
默认的拷贝构造函数,编译器提供
把对象1的属性拷贝给对象二
把指针变量的值拷贝给对象二,并没有把指针变量所指向的内存空间的数据拷贝过来
两个指针变量指向同一个空间
obj2析构函数 把指向的内存空间析构
obj2 指向null,obj1仍然指向堆里被释放的内存空间。
obj1再析构,还是析构的obj2之前析构的那一块空间,,结果析构两次,造成空间的coredump
coredump出现原因:
等号操作也是浅拷贝操作
临时对象
生命周期
构造之后马上析构
构造函数中调用构造函数
危险行为
new 和delete
基本语法
1 | int *arr = new int[10]; |
面向对象
友元函数和友元类
友元函数
1 | #include<iostream> |
友元类
重载运算符
这两个都写在vs里了
继承
概念
访问父类的语法和概念
派生类的访问控制
1 | 类的单个类访问控制 |
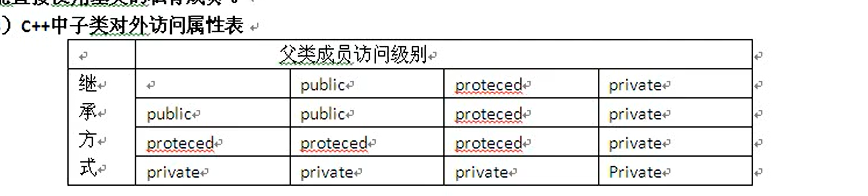
protect 关键字修饰变量使用,是为了继承
继承中构造和析构
1 | //赋值兼容性原则 |


继承和虚函数
virtual函数:你希望derived class 重新定义它,且你对他已有默认定义
pure virtual 函数:erived class 重新定义它,且你对他没有默认定义
复合和继承
委托和继承
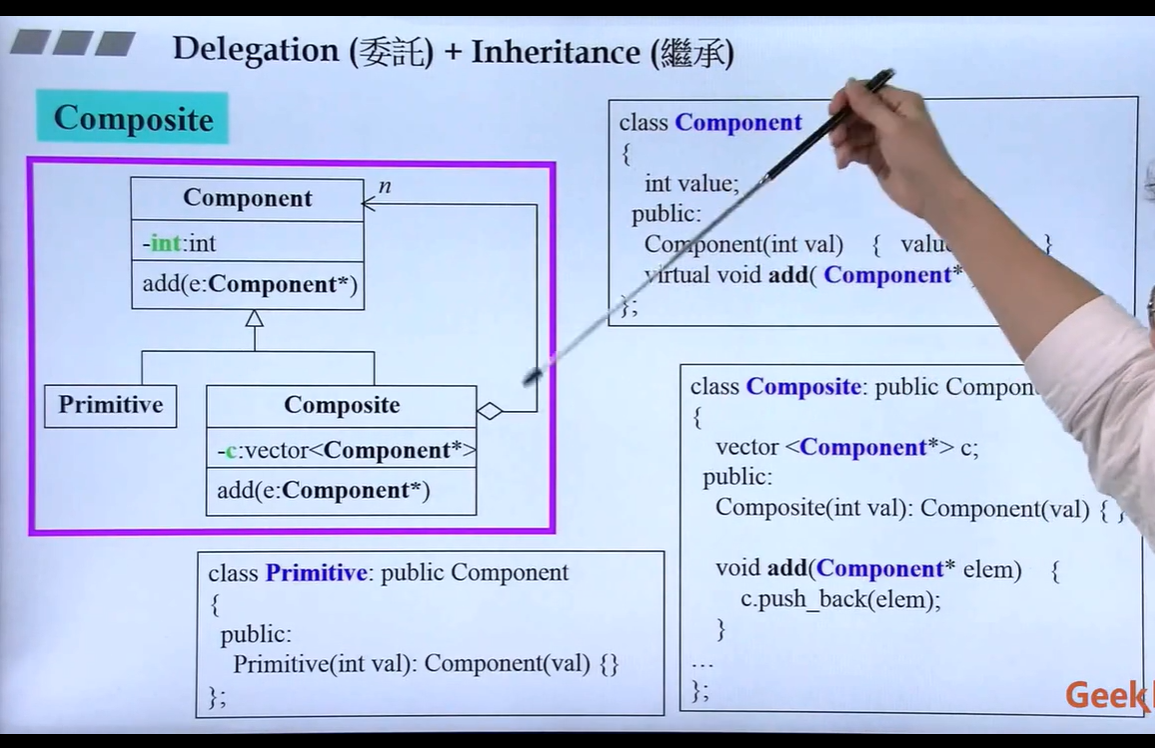
抽象基类
1 | class person//抽象基类(类似于接口) |
设计抽象类(通常称为 ABC)的目的,是为了给其他类提供一个可以继承的适当的基类。抽象类不能被用于实例化对象,它只能作为接口使用。如果试图实例化一个抽象类的对象,会导致编译错误。
因此,如果一个 ABC 的子类需要被实例化,则必须实现每个纯虚函数,这也意味着 C++ 支持使用 ABC 声明接口。如果没有在派生类中重写纯虚函数,就尝试实例化该类的对象,会导致编译错误。
可用于实例化对象的类被称为具体类。https://www.runoob.com/cplusplus/cpp-interfaces.html
继承的动态内存分配
基类使用动态内存分配,派生类不使用动态内存分配。
可以省略构造函数和析构函数中的内存分配和释放操作,直接继承基类中的构造和析构函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32class Base {
public:
Base(const char* str) {
data_ = new char[strlen(str) + 1];
strcpy(data_, str);
}
virtual ~Base() {
delete[] data_;
}
const char* getData() const {
return data_;
}
private:
char* data_;
};
// 派生类,不使用动态内存分配
class Derived : public Base {
public:
Derived(const char* str, int value)
: Base(str), value_(value) {}
int getValue() const {
return value_;
}
private:
int value_;
};
基类使用动态内存分配,派生类也使用动态内存分配1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53class BASE
{
private:
char* base;
public:
BASE(const char *str)
{
base = new char[strlen(str) + 1];
strcpy(base, str);
}
virtual ~BASE()
{
delete[]base;
}
BASE& operator=(const BASE& str)
{
if (this == &str)
{
return *this;
}
delete[]base;
base = new char[strlen(str.base) + 1];
strcpy(base,str.base);
return *this;
}
};
class derived :public BASE
{
private:
char* dervived;
public:
derived(const char* str):BASE(str)
{
dervived = new char[strlen(str) + 1];
strcpy(dervived, str);
}
derived& operator=(const derived& str)
{
if (this == &str)
{
return *this;
}
delete[]dervived;
BASE::operator=(str);
dervived = new char[strlen(str.dervived) + 1];
strcpy(dervived, str.dervived);
return *this;
}
~derived()
{
delete[] dervived;
}
};
conversion function
1 | class fraction |
double d = 4 + f;这一语句会首先查找Fraction是否有重载操作符 operator + (double, Fraction) 的函数,由于没有,所以调用会转换函数operator double() const。
另外,转换函数除了可以将一个类型转换成另一个基本类型,还可以将一个类型转换成另一个复合类型(例如string类型)。
non -explicit-one-argument ctor
1 | class Fraction |
只要一个实参就够了,也可以传两个实参。将别的东西转换成这个类对象
conversion function vs. non-explicit-one-argument constructor
explicit-one-argument constructor
1 | class Fraction |
由于在构造函数前面增加了explicit关键字,所以不能将4转换成Fraction类型;也不能先将f转换成double类型,与4相加后再将double转换成Fraction。
pointer like classes
智能指针
智能指针是你在堆栈上声明的类模板,并可通过使用指向某个堆分配的对象的原始指针进行初始化。 在初始化智能指针后,它将拥有原始的指针。 这意味着智能指针负责删除原始指针指定的内存。 智能指针析构函数包括要删除的调用,并且由于在堆栈上声明了智能指针,当智能指针超出范围时将调用其析构函数,尽管堆栈上的某处将进一步引发异常。
C++ 中有三种常用的智能指针:
unique_ptr:独占所有权的智能指针,不能被复制,只能被移动。当 unique_ptr 超出作用域时,它所指向的对象会被自动释放。
shared_ptr:共享所有权的智能指针,可以被多个 shared_ptr 共享。当最后一个 shared_ptr 超出作用域时,它所指向的对象会被自动释放。
weak_ptr:弱引用的智能指针,不能直接访问所指向的对象,必须通过 lock() 函数获得一个 shared_ptr 才能访问。weak_ptr 不会增加所指对象的引用计数,因此不会影响所指对象的生命周期。
shared_ptr
用法:1
2
3#include<memory>
shared_ptr<double> p1(new double(42));
shared_ptr<int>p2= make_shared<int>(42);
拷贝和赋值1
2
3
4
5auto r = make_shared<int>(42);//r指向int只有一个引用
r=q;//给r赋值
//q指向的对象引用次数++
//r指向对象引用次数--
//r没有引用了,就会自动释放
离开作用域,它指向内存也会自动释放
但是如果有其他智能指针也指向这块内存,他就不会被释放1
2
3
4
5void use_factory(T arg)
{
shared_ptr<Foo> p = factory(arg);
return p;//引用计数增加
}//离开作用域但不会被释放
迭代器
fuction like classes
模板
类模板
函数模板
成员模板

模板特化
1 | template<> |
偏特化(局部特化)
1 | template<class T,class alloc> |
范围的偏1
2
3
4
5
6
7
8
9template<class T>
class c
{
};
template<class T>
class c<T*>
{
};
如果使用者使用的是指针就用第二个模板
如果不是指针,用的是第一个模板
模板模板参数
1 | template<class T,template<class T> class smartptr> |
三个主题
pack
1 | template<typename T,typename...Types> |
用sizeof…(args)可以知道包有多少
auto
auto声明变量必须要赋值
ranged-base for
1 | vector<double> vec; |
reference
1 | int x = 0; |
reference一定要有初值,只能代表一个,不能代表其他
32位电脑指针占四个字节
参数传递
this
重载new(),delete()
1 | class Foo { |
在类中的operator new默认就是static。所以加static可以,不加也是全局,可以正常使用。
这种重载的意义是和重载operator new配套。只有operator new报异常了,就会调用对应的operator delete。若没有对应的operator delete,则无法释放内存。
STL
学习网址:zh.cppreference.com
容器
array
相比于普通数组,array容器访问速度快,安全性高,在传递方式方面,普通数组作为函数参数时,实际上是传递一个指向数组首元素的指针。而array容器作为函数参数时,实际上传递的是整个array容器的值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20td::array<int, 5> myarr;
std::array<int, 5> a2;
for (int i =0;i<myarr.size();i++)
{
std::cin >> myarr[i];
}
for (auto it = myarr.begin(); it != myarr.end(); it++)
{
std::cout << *it << " ";
}
std::cout << "\n";
std::sort(myarr.begin(),myarr.end());//算法库
std::ostream_iterator<int> output(std::cout," ");
std::reverse_copy(myarr.begin(), myarr.end(), a2.begin());
std::reverse_copy(myarr.begin(), myarr.end(), output);
std::array<std::string, 5> a3 = { "aefea",std::string("a") };
for (auto& s : a3)
{
std::cout << s << " ";
}
上述代码中,sort是algorithm库中函数,能将容器内元素从大到小排序,reversecopy函数详见cppconference
vector
能动态调整大小,存储相同类型元素1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21std::vector<int> vec;
std::vector<int> vec2(5);
std::vector<int> vec3(5, 42);
std::vector<int> vec4(vec3);
vec.push_back(10);
vec.push_back(20);
//vec.pop_back();//删除末尾元素
int first = vec[0]; // 使用数组下标访问元素
int second = vec.at(1); // 使用at()方法访问元素,会检查下标是否越界
//获取容量
size_t size = vec.size();//获取向量大小
size_t capacity = vec.capacity();//分配内存空间大小
//迭代访问
for (auto i : vec)
{
std::cout << i<<std::endl;
}
for (auto it = vec.begin(); it != vec.end(); it++)
{
std::cout << *it << std::endl;
}
data()返回值 : 指向底层元素存储的指针。对于非空容器,返回的指针与首元素地址比较相等。
例子:1
2
3
4
5
6
7
8
9
10
11
12void span_func(std::span<const int> data) // C++20 起
{
std::cout << "data = ";
for (const int e : data)
std::cout << e << ' ';
std::cout << '\n';
}
int main()
{
std::span<int> s{container.data(),container.size() };
span_func(s);
}
注:span 是c++20新特性
list
双向链表1
2
3
4
5
6
7
8
9
10
11
12std::list<int> l = {7,5,16,8};
l.push_back(25);//添加末尾
l.push_front(15);// 开头
std::list<int>::iterator it = std::find(l.begin(),l.end(),16);//用迭代器找到16的位置
if(it!=l.end())
l.insert(it, 42);
std::cout << *it<<"\n";
//迭代打印
for (auto i : l)
{
std::cout << i << " ";
}
还有pop_back等用法在笔记中不一 一实例了,cppconference中有实例。
list 的原理:
list 是通过双向链表实现的,每个节点都包含了指向前一个节点和后一个节点的指针。因此,插入和删除元素时只需要修改相关节点的指针即可,不需要像数组那样进行元素的移动。
由于 list 中的元素是通过指针进行连接的,因此在访问 list 中的元素时,需要通过迭代器来进行访问。迭代器是指向 list 中元素的指针,支持 ++ 操作来遍历 list 中的元素
forward list
单向列表(单链表)
只能从一端进入和移除,所以只能从容器起始插入和删除
queue(容器的适配器 )
队列
queue是一个单口进出的数据结构,没有迭代器
first in first out
deque
双端队列
可以两边扩充
在 C++ STL 中,deque(双端队列)是一种常用的容器,它可以在两端进行插入和删除操作,并且支持随机访问。deque 内部使用一个动态数组来存储元素,可以动态调整大小以适应元素的添加和删除,同时还可以在数组的两端进行快速插入和删除操作,因此可以高效地实现队列和栈等数据结构。
简单用法例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14std::deque<int> de(10);
/*de.push_back(5);
de.push_front(10);*/
std::deque<int>::iterator it = de.begin();
for (it; it != de.end(); it++)
{
int x = 0;
std::cin >> x;
*it = x;
}
for (auto i : de)
{
std::cout << i;
}
stack(容器的适配器)
栈和队列都是不能直接通过构造函数分配元素数量的,必须通过封装vector来实现
具体例子:1
2std::vector<int> v(10, 0);
std::stack<int> s(v);
set 红黑树
set 中存储的元素是唯一的,插入重复元素会被忽略
multiset(红黑树)
含有 Key 类型对象有序集的容器。与 set 不同,它允许多个 Key 拥有等价的值。用关键比较函数 Compare 进行排序。搜索、插入和移除操作拥有对数复杂度。
unordered_multiset(哈希表)
篮子不能太长,如果元素的个数大于等于篮子,篮子就要重新扩充大于等于两倍的元素个数
unordered_set (哈希表)
四个容器区别总结
set 和 multiset 是基于红黑树实现的关联容器,可以快速插入、删除、查找元素,并且元素默认按照元素值从小到大排序,但插入、删除和查找等操作的时间复杂度为 O(log n)。
unordered_set 和 unordered_multiset 是基于哈希表实现的关联容器,可以快速插入、删除、查找元素,并且插入、删除和查找等操作的时间复杂度为 O(1),但元素没有固定的顺序。
在选择使用哪种容器时,需要考虑元素是否需要排序以及对性能的要求。如果元素需要排序,且对性能要求不是非常高,可以选择 set 或 multiset;如果对性能要求比较高,可以选择 unordered_set 或 unordered_multiset。
四个容器的用法:
1 |
|
map
Map是C++ STL中的一个关联式容器,它提供了一种映射关系的数据结构,即一组key-value对,其中key是唯一的,value可以重复。Map中的元素是按照key的大小进行排序的,因此可以进行快速的查找和插入操作。Map支持[]和insert等操作,可以通过迭代器进行遍历。Map的底层实现一般采用红黑树,因此它的插入、删除和查找操作的时间复杂度都是O(log n)。
用法:1
2
3
4
5
6
7
8
9
10
11
12
13
14/*插入,创建,初始化,修改*/
std::map<std::string, int> m{ {"CPU",10} ,{"GPU",20}};
m.insert(std::pair<std::string, int>("ARM", 35));//插入
m["ARM"] = 45;
m["Map"] = 15;//插入新值
/*遍历方法*/
for (const auto& [key, value] : m)
std::cout << '[' << key << "] = " << value << "; ";
for (auto it = m.begin(); it != m.end(); it++)
{
std::cout << it->first << " " << it->second;
}
multimap
Multimap是一个允许重复键的Map,它也是一个关联式容器,提供了一种映射关系的数据结构,其中一组key-value对中的key可以重复,而value可以不重复。Multimap的元素同样是按照key的大小进行排序的,并且支持[]和insert等操作,可以通过迭代器进行遍历。Multimap的底层实现一般采用红黑树,因此它的插入、删除和查找操作的时间复杂度也都是O(log n)。
用法:1
2
3
4
5
6
7
8
9//2.multimap
std::multimap<std::string, int> m;
m.insert(std::pair<std::string, int>("map", 10));
m.insert(std::pair<std::string, int>("map", 10));
m.insert(std::pair<std::string, int>("map", 10));
//m["map"] = 15;//没有[]操作符 error
for (auto it = m.begin(); it != m.end(); it++) {
std::cout << it->first << " : " << it->second <<std:: endl;
}
Multimap的用法和Map类似,只是插入操作不会覆盖已有的键值对。
unordered_multimap
unordered_multimap是一个允许重复键的unordered_map,它也是一个哈希表,提供了一种映射关系的数据结构,其中一组key-value对中的key可以重复,而value可以不重复。unordered_multimap中的元素是按照哈希值进行存储的,因此查找和插入操作的时间复杂度是O(1)。
用法:
unordered_map的用法和Map类似,只是底层实现不同,插入操作的时间复杂度为O(1)。
unordered_map
unordered_map是C++ STL中的一个哈希表,它提供了一种映射关系的数据结构,其中一组key-value对中的key是唯一的,而value可以重复。unordered_map中的元素是按照哈希值进行存储的,因此查找和插入操作的时间复杂度是O(1)。
用法:
unordered_multimap的用法和unordered_map类似,只是允许键值对中的键重复。
区别总结
Map和Multimap都是基于红黑树实现的,而unordered_map和unordered_multimap都是基于哈希表实现的。因此,Map和Multimap的插入、删除和查找操作的时间复杂度都是O(log n),而unordered_map和unordered_multimap的插入、删除和查找操作的时间复杂度都是O(1)。另外,Map和Multimap中的元素是按照key的大小进行排序的,而unordered_map和unordered_multimap中的元素是按照哈希值进行存储的,因此它们的遍历顺序可能不同。此外,Multimap和unordered_multimap允许重复键,而Map和unordered_map不允许重复键。
补充stl算法
upper_bound
1 | std::vector<int> v = {1, 2, 3, 4, 4, 6, 7, 8, 9}; |
std::upper_bound将返回一个迭代器,指向第一个大于value的元素。如果不存在这样的元素,std::upper_bound将返回last。