
堆叠式工作流
堆叠式工作流
堆叠式 PR。堆叠式 diff。堆叠式变更。
一种更好的拉取请求(Pull Request)管理方式。
代码评审很耗时
代码评审对 PR 作者和评审者来说都可能耗费很长时间。
作为作者,你可能要等上几个小时、几天,甚至几年,才能把改动合并。这对跨时区的分布式团队尤其棘手:你正想发布一个功能,但评审人还在地球另一端睡觉,只能干等。
等到同事终于醒来,留了几条评论、请求一些更改,你又得开始迭代,整个循环重新来过。
对评审者而言,代码评审同样花时间。想写出有价值的评审需要付出相当多的精力,尤其当 PR 体量很大时。一次彻底的评审意味着要通读变更、建立上下文、留下评论与建议,然后再等待作者回应。
代码评审让你变慢
等待队友评审你的 PR 会让你放缓脚步,任何依赖这份代码的工作也都被阻塞。
在等待评审的时间里,你本可以做这些事情:
- 发布有影响力的新功能
- 处理你一直搁置的技术债杂务
- 去海边
堆叠让你免去等待
堆叠(Stacking)把你的开发与评审并行化,因此你无需等前一个改动合并,才能在其之上继续构建。
想象你在做一个功能,既需要新增后端接口,又需要前端改动。你刚在一个新功能分支上写完创建接口的 PR。在传统工作流里,接下来你得先把这个 PR 评审、合并进 main,然后再从 main 分支出新分支,最后才能开始开发依赖该接口的前端改动——真折腾。
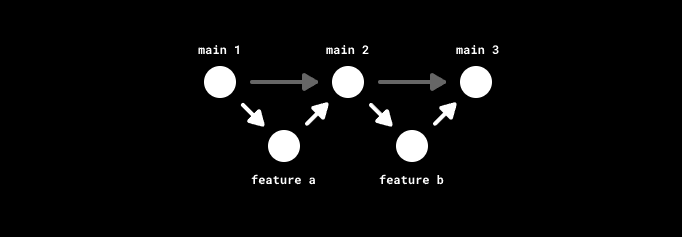
(图示:未使用堆叠的分支模型。)
用了堆叠,你不用这样做。把后端改动提交评审,同时新建一个依赖分支,继续往下做。
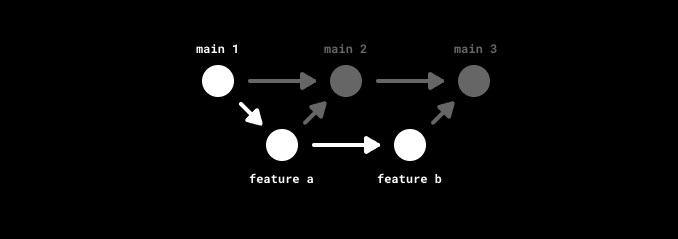
(图示:使用堆叠的分支模型。)
当两个 PR 都通过评审后,你可以一起落地,也可以分别落地。栈的结构决定了变更可以有先后顺序;比如这个例子里,新的后端接口可以先于调用它的前端改动落地,是安全的。
这种“关注点分离”不是堆叠自动魔法完成的,而是因为堆叠迫使开发者把一个大改动拆解成一连串更小、相互依赖的改动。
手动堆叠很难
由于堆叠 PR 彼此有依赖,一旦上游发生变化,为了保持同步,栈里后续的每个 PR 都需要递归地在彼此之上 rebase。
手动做并非不可能,但 Git 的 CLI 并不是为这种工作流设计的。你得对每个分支分别 rebase,非常耗时;同时还要处理级联的合并冲突,整个过程会变得更混乱。
堆叠工具
好在有一些工具能把复杂度自动化,显著简化流程:
- Graphite
在 GitHub 上开箱即用的堆叠方案:提供 CLI、VS Code 扩展和用于管理栈的 Web UI。与 GitHub 完整同步,即使你是团队里第一个尝试堆叠的人也能使用。
了解更多:graphite.dev → - ghstack
面向 GitHub 的开源 CLI。简化了创建、更新与推送堆叠提交到 GitHub 的过程(抽象了分支的细节)。
了解更多:github.com → - git town
高层次的 Git CLI,支持打开和同步分支到 GitHub。
了解更多:git-town.com → - Sapling
来自 Meta 的新一代版本控制系统,内置对堆叠的支持。
了解更多:sapling-scm.com → - spr
另一款面向 GitHub 的开源 CLI,与 ghstack 在本质上很相似。以“无花哨”的方式创建与更新 PR。(要求每个 PR 仅包含一个提交。)
了解更多:ejoffe.github.io →
如果你不想用这些工具,Git 本身也在不断增强对堆叠的支持。新的 --update-refs 选项能让你用更少的 rebase 更新整个栈;不过,堆叠流程的部分环节仍然比较繁琐(例如在 GitHub 或其他平台上打开 PR)。
一旦开始堆叠,你就回不去
抛开工具不谈,你应该更频繁地堆叠。
除了改变分支结构,堆叠还会迫使你更有条理地组织思路,让改动对你自己、评审者以及后续任何开发者(无论是想学习、理解还是回滚)来说都更容易读懂。堆叠能显著提升代码质量,让所有人的工作都更轻松。
你几乎可以在任何仓库里立刻开始堆叠。堆叠与这些因素无关:编程语言、前端/后端、你是 rebase 还是 merge、你是 commit 还是 amend、你用单仓还是多仓。
许多开始堆叠的人,常常会形成由 5–10 个 PR 组成的栈,因为几乎每个“大改动”都能更好地被拆分为小而连贯的一串改动。如果这个数字让你有点紧张,工具能让它更容易上手;但无论是否使用工具,最重要的是先开始堆叠。